

Adafactor Explained
This article is me trying to clarify the intuition behind the innovation of Adafactor [Shazeer & Stern 2018 https://arxiv.org/abs/1804.04235] to myself, hopefully this can prove useful to other people as well. Please let me know if anything is incorrect or unclear.
So Adafactor is a relatively new improvement on stochastic optimization techniques used to train neural networks(nn), it improves upon ADAM, which itself is an improvement on vanilla Stochastic Gradient Descent (SGD). If you are unfamiliar with these concepts I would recommend you to read this article, before coming back to this piece. Don't worry I will wait.
So vanilla SGD is used to update the weights of a nn to increase its accuracy iteratively. A problem that can occur with SGD is that an update of the weights is either too large or too small and one can get stuck in a local optimum when training or skip passed where you want to be. To visualize the different trajectories of the different optimization algorhitmes have a look at this link
ADAM mostly solves these problems by introducing two momentum factors of the first moment and the second moment multiplied by parameters beta-hat1 and beta-hat2. To be exact these momentum factors are the inverse squared roots of the exponential squared roots of the past gradients.
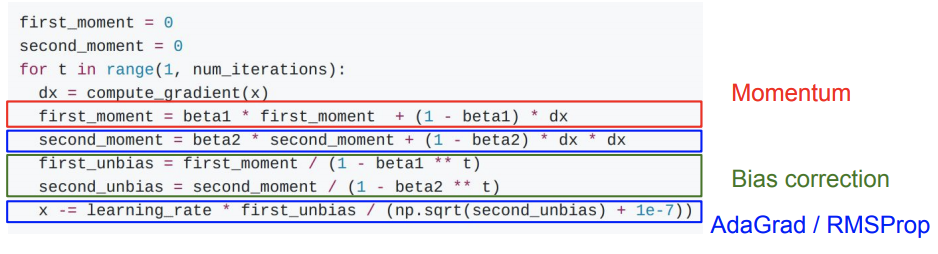
Taken from CS231n: Convolutional Neural Networks for Visual Recognition Stanford lecture 7 slides (http://cs231n.stanford.edu/syllabus.html , http://cs231n.stanford.edu/slides/2019/cs231n_2019_lecture07.pdf)
This results in a much smoother descent, better training and results. However the problem of ADAM is that it also requires to keep these values for each parameter, hence creating a large burden on the hardware when training larger and larger networks. Moreover, it has been shown that often larger networks do perform better, hence the need to try and eliminate this bottleneck. Shazeer and Stern have shown that they can alleviate this problem without impacting performance with Adafactor.
Adafactor does this through 4 innovations:
1. It drops the first momentum and beta-hat1 entirely
2. Update clipping & gradually, increase the decay rate scheme
3. Maintaining only the per-row and per-column sums of the moving averages, and estimating the per parameter second moments based on these sums
4. Scale the parameter updates based on the scale of the parameters themselves
So let's dive a bit deeper in each of these. 1 is pretty self-explanatory the first moments are no longer stored or considered.
The second innovation means scaling down the update to the weights in some cases, to prevent larger than warranted updates. Specifically when the RMS (root mean square) of Ut exceeds a threshold value d. The second part is that is we gradually change the beta-hat2 depending on t. At the start we are at 0 and increase towards 1 as t tends to infinity.
This results in a gain of the stability of a low beta-hat2 at the start, while realising gains in performance due to a high beta-hat2 later in the run.
The third innovation entails that we maintain only sums of the moving averages instead of specifics and estimate based on this.
we keep running averages of the row sums Rt and column sums Ct of the squared gradients. The full accumulator is then approximated as the outer product divided by the sum of all entries, Rt * Ct / 1n1 * Rt and is subsequently scaled by the same bias correction factor as in Adam.
Finally, the last improvement results in not taking absolute step sizes {at}t=1T but instead relative step sizes {⍴t}t=1T which get multiplied by the scale of the parameters. This scale is basically the RMS of the components of the vector or matrix with a lower bound of small constant epsilon_2. We do not want to stay stuck at 0 if we do not have this lower bound.
Adding this all up results in the following:

Thank you for reading, hopefully this was at least somewhat useful. If you want to hear more from me please follow me on twitter @oswinfrans to see more ramblings on machine learning and tech.
References:
- Adafactor paper https://arxiv.org/abs/1804.04235
- Tensor2tensor https://github.com/tensorflow/tensor2tensor/tree/master/tensor2tensor
- Neural network introduction https://victorzhou.com/blog/intro-to-neural-networks/
- CS231n: Convolutional Neural Networks for Visual Recognition http://cs231n.stanford.edu/syllabus.html
- Optimization visualization tool https://bl.ocks.org/EmilienDupont/aaf429be5705b219aaaf8d691e27ca87